
Notes: This article on Nature, you can find it here https://www.nature.com/articles/s41562-017-0189-z . I have copied it here for personal learning only
We propose to change the default P-value threshold for statistical significance from 0.05 to 0.005 for claims of new discoveries.
The lack of reproducibility of scientific studies has caused growing concern over the credibility of claims of new discoveries based on ‘statistically significant’ findings. There has been much progress toward documenting and addressing several causes of this lack of reproducibility (for example, multiple testing, P-hacking, publication bias and under-powered studies). However, we believe that a leading cause of non-reproducibility has not yet been adequately addressed: statistical standards of evidence for claiming new discoveries in many fields of science are simply too low. Associating statistically significant findings with P < 0.05 results in a high rate of false positives even in the absence of other experimental, procedural and reporting problems.
For fields where the threshold for defining statistical significance for new discoveries is P < 0.05, we propose a change to P < 0.005. This simple step would immediately improve the reproducibility of scientific research in many fields. Results that would currently be called significant but do not meet the new threshold should instead be called suggestive. While statisticians have known the relative weakness of using P ≈ 0.05 as a threshold for discovery and the proposal to lower it to 0.005 is not new1,2, a critical mass of researchers now endorse this change.
We restrict our recommendation to claims of discovery of new effects. We do not address the appropriate threshold for confirmatory or contradictory replications of existing claims. We also do not advocate changes to discovery thresholds in fields that have already adopted more stringent standards (for example, genomics and high-energy physics research; see the ‘Potential objections’ section below).
We also restrict our recommendation to studies that conduct null hypothesis significance tests. We have diverse views about how best to improve reproducibility, and many of us believe that other ways of summarizing the data, such as Bayes factors or other posterior summaries based on clearly articulated model assumptions, are preferable to P values. However, changing the P value threshold is simple, aligns with the training undertaken by many researchers, and might quickly achieve broad acceptance.
Strength of evidence from P values
In testing a point null hypothesis H0 against an alternative hypothesis H1 based on data xobs, the P value is defined as the probability, calculated under the null hypothesis, that a test statistic is as extreme or more extreme than its observed value. The null hypothesis is typically rejected — and the finding is declared statistically significant — if the P value falls below the (current) type I error threshold α = 0.05.
From a Bayesian perspective, a more direct measure of the strength of evidence for H1 relative to H0 is the ratio of their probabilities. By Bayes’ rule, this ratio may be written as:
(1)
where BF is the Bayes factor that represents the evidence from the data, and the prior odds can be informed by researchers’ beliefs, scientific consensus, and validated evidence from similar research questions in the same field. Multiple-hypothesis testing, P-hacking and publication bias all reduce the credibility of evidence. Some of these practices reduce the prior odds of H1 relative to H0 by changing the population of hypothesis tests that are reported. Prediction markets3 and analyses of replication results4 both suggest that for psychology experiments, the prior odds of H1 relative to H0 may be only about 1:10. A similar number has been suggested in cancer clinical trials, and the number is likely to be much lower in preclinical biomedical research5.
There is no unique mapping between the P value and the Bayes factor, since the Bayes factor depends on H1. However, the connection between the two quantities can be evaluated for particular test statistics under certain classes of plausible alternatives (Fig. 1).
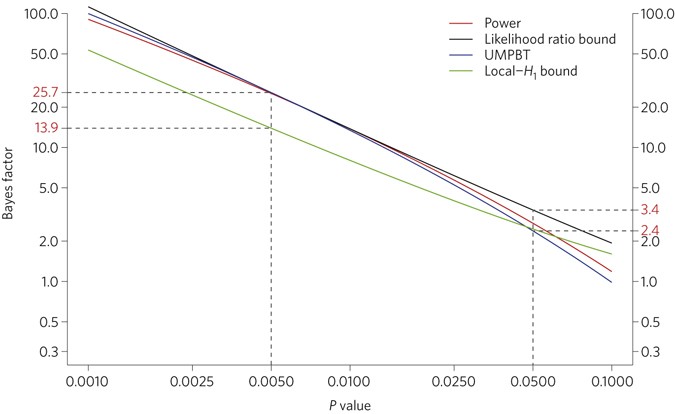
The Bayes factor (BF) is defined as . The figure assumes that observations are independent and identically distributed (i.i.d.) according to x ~ N(μ,σ 2), where the mean μ is unknown and the variance σ 2 is known. The P value is from a two-sided z-test (or equivalently a one-sided -test) of the null hypothesis H 0: μ = 0. Power (red curve): BF obtained by defining H 1 as putting ½ probability on μ = ±m for the value of m that gives 75% power for the test of size α = 0.05. This H 1 represents an effect size typical of that which is implicitly assumed by researchers during experimental design. Likelihood ratio bound (black curve): BF obtained by defining H 1 as putting ½ probability on μ = ±, where is approximately equal to the mean of the observations. These BFs are upper bounds among the class of all H 1 terms that are symmetric around the null, but they are improper because the data are used to define H 1. UMPBT (blue curve): BF obtained by defining H 1 according to the uniformly most powerful Bayesian test2 that places ½ probability on μ = ±w, where wis the alternative hypothesis that corresponds to a one-sided test of size 0.0025. This curve is indistinguishable from the ‘Power’ curve that would be obtained if the power used in its definition was 80% rather than 75%. Local-H 1 bound (green curve): , where pis the P value, is a large-sample upper bound on the BF from among all unimodal alternative hypotheses that have a mode at the null and satisfy certain regularity conditions15. The red numbers on the y axis indicate the range of Bayes factors that are obtained for P values of 0.005 or 0.05. For more details, see the Supplementary Information.
A two-sided P value of 0.05 corresponds to Bayes factors in favour of H1that range from about 2.5 to 3.4 under reasonable assumptions about H1(Fig. 1). This is weak evidence from at least three perspectives. First, conventional Bayes factor categorizations6 characterize this range as ‘weak’ or ‘very weak’. Second, we suspect many scientists would guess that P ≈ 0.05 implies stronger support for H1 than a Bayes factor of 2.5 to 3.4. Third, using equation (1) and prior odds of 1:10, a P value of 0.05 corresponds to at least 3:1 odds (that is, the reciprocal of the product ) in favour of the null hypothesis!
Why 0.005
The choice of any particular threshold is arbitrary and involves a trade-off between type I and type II errors. We propose 0.005 for two reasons. First, a two-sided P value of 0.005 corresponds to Bayes factors between approximately 14 and 26 in favour of H1. This range represents ‘substantial’ to ‘strong’ evidence according to conventional Bayes factor classifications6.
Second, in many fields the P < 0.005 standard would reduce the false positive rate to levels we judge to be reasonable. If we let φ denote the proportion of null hypotheses that are true, 1 – β the power of tests in rejecting false null hypotheses, and α the type I error/significance threshold, then as the population of tested hypotheses becomes large, the false positive rate (that is, the proportion of true null effects among the total number of statistically significant findings) can be approximated by:
(2)
For different levels of the prior odds that there is a true effect, , and for significance thresholds α = 0.05 and α = 0.005, Fig. 2 shows the false positive rate as a function of power 1−β.
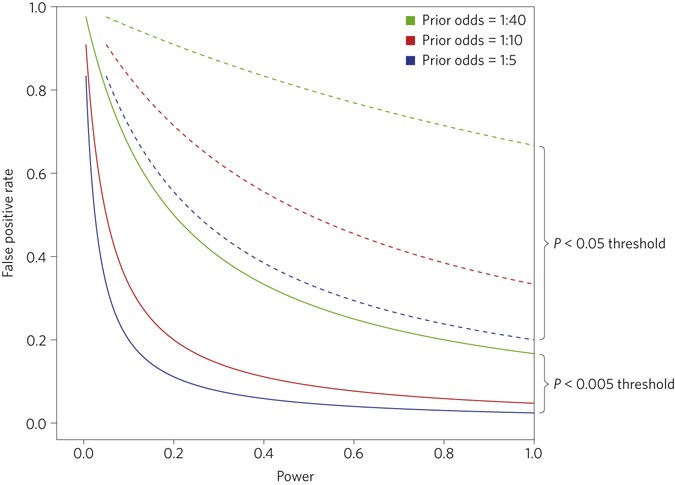
Calculated according to equation (2), with prior odds defined as . For more details, see the Supplementary Information.
In many studies, statistical power is low7. Figure 2 demonstrates that low statistical power and α = 0.05 combine to produce high false positive rates.
For many, the calculations illustrated by Fig. 2 may be unsettling. For example, the false positive rate is greater than 33% with prior odds of 1:10 and a P value threshold of 0.05, regardless of the level of statistical power. Reducing the threshold to 0.005 would reduce this minimum false positive rate to 5%. Similar reductions in false positive rates would occur over a wide range of statistical powers.
Empirical evidence from recent replication projects in psychology and experimental economics provide insights into the prior odds in favour of H1. In both projects, the rate of replication (that is, significance at P < 0.05 in the replication in a consistent direction) was roughly double for initial studies with P < 0.005 relative to initial studies with 0.005 < P < 0.05: 50% versus 24% for psychology8, and 85% versus 44% for experimental economics9. Although based on relatively small samples of studies (93 in psychology, and 16 in experimental economics, after excluding initial studies with P > 0.05), these numbers are suggestive of the potential gains in reproducibility that would accrue from the new threshold of P < 0.005 in these fields. In biomedical research, 96% of a sample of recent papers claim statistically significant results with the P < 0.05 threshold10. However, replication rates were very low5 for these studies, suggesting a potential for gains by adopting this new standard in these fields as well.
Potential objections
We now address the most compelling arguments against adopting this higher standard of evidence.
The false negative rate would become unacceptably high
Evidence that does not reach the new significance threshold should be treated as suggestive, and where possible further evidence should be accumulated; indeed, the combined results from several studies may be compelling even if any particular study is not. Failing to reject the null hypothesis does not mean accepting the null hypothesis. Moreover, the false negative rate will not increase if sample sizes are increased so that statistical power is held constant.
For a wide range of common statistical tests, transitioning from a Pvalue threshold of α = 0.05 to α = 0.005 while maintaining 80% power would require an increase in sample sizes of about 70%. Such an increase means that fewer studies can be conducted using current experimental designs and budgets. But Fig. 2 shows the benefit: false positive rates would typically fall by factors greater than two. Hence, considerable resources would be saved by not performing future studies based on false premises. Increasing sample sizes is also desirable because studies with small sample sizes tend to yield inflated effect size estimates11, and publication and other biases may be more likely in an environment of small studies12. We believe that efficiency gains would far outweigh losses.
The proposal does not address multiple-hypothesis testing, P-hacking, publication bias, low power, or other biases (for example, confounding, selective reporting, and measurement error), which are arguably the bigger problems
We agree. Reducing the P value threshold complements — but does not substitute for — solutions to these other problems, which include good study design, ex ante power calculations, pre-registration of planned analyses, replications, and transparent reporting of procedures and all statistical analyses conducted.
The appropriate threshold for statistical significance should be different for different research communities
We agree that the significance threshold selected for claiming a new discovery should depend on the prior odds that the null hypothesis is true, the number of hypotheses tested, the study design, the relative cost of type I versus type II errors, and other factors that vary by research topic. For exploratory research with very low prior odds (well outside the range in Fig. 2), even lower significance thresholds than 0.005 are needed. Recognition of this issue led the genetics research community to move to a ‘genome-wide significance threshold’ of 5 × 10–8 over a decade ago. And in high-energy physics, the tradition has long been to define significance by a ‘5-sigma’ rule (roughly a P value threshold of 3 × 10–7). We are essentially suggesting a move from a 2-sigma rule to a 3-sigma rule.
Our recommendation applies to disciplines with prior odds broadly in the range depicted in Fig. 2, where use of P < 0.05 as a default is widespread. Within those disciplines, it is helpful for consumers of research to have a consistent benchmark. We feel the default should be shifted.
Changing the significance threshold is a distraction from the real solution, which is to replace null hypothesis significance testing (and bright-line thresholds) with more focus on effect sizes and confidence intervals, treating the P value as a continuous measure, and/or a Bayesian method.
Many of us agree that there are better approaches to statistical analyses than null hypothesis significance testing, but as yet there is no consensus regarding the appropriate choice of replacement. For example, a recent statement by the American Statistical Association addressed numerous issues regarding the misinterpretation and misuse of P values (as well as the related concept of statistical significance), but failed to make explicit policy recommendations to address these shortcomings13. Even after the significance threshold is changed, many of us will continue to advocate for alternatives to null hypothesis significance testing.
Concluding remarks
Ronald Fisher understood that the choice of 0.05 was arbitrary when he introduced it14. Since then, theory and empirical evidence have demonstrated that a lower threshold is needed. A much larger pool of scientists are now asking a much larger number of questions, possibly with much lower prior odds of success.
For research communities that continue to rely on null hypothesis significance testing, reducing the P value threshold for claims of new discoveries to 0.005 is an actionable step that will immediately improve reproducibility. We emphasize that this proposal is about standards of evidence, not standards for policy action nor standards for publication. Results that do not reach the threshold for statistical significance (whatever it is) can still be important and merit publication in leading journals if they address important research questions with rigorous methods. This proposal should not be used to reject publications of novel findings with 0.005 < P < 0.05 properly labelled as suggestive evidence. We should reward quality and transparency of research as we impose these more stringent standards, and we should monitor how researchers’ behaviours are affected by this change. Otherwise, science runs the risk that the more demanding threshold for statistical significance will be met to the detriment of quality and transparency.
Journals can help transition to the new statistical significance threshold. Authors and readers can themselves take the initiative by describing and interpreting results more appropriately in light of the new proposed definition of statistical significance. The new significance threshold will help researchers and readers to understand and communicate evidence more accurately.
Nhận xét